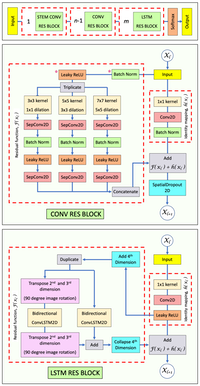

Res-CR-Net is a neural network featuring a novel FCN architecture, with very good performance in multiclass segmentation tasks of both electron (gray scale, 1 channel) and light microscopy (rgb color, 3 channels) images of relevance in the analysis of pathology specimens. Res-CR-Net offers some advantages with respect to other networks inspired to an encoder-decoder architecture, as it is completely modular, with residual blocks that can be proliferated as needed, and it can process images of any size and shape without changing layers size and operations. Res-CR-Net can be particularly effective in segmentation tasks of biological images, where the labeling of ground truth classes is laborious, and thus the number of annotated/labeled images in the training set is small.
Res-CR-Net combines two types of residual blocks:
CONV RES BLOCK. The traditional U-Net backbone architecture, with its the encoder-decoder paradigm, is replaced by a series of modified residual blocks, each consisting of three parallel branches of separable + atrous convolutions with different dilation rates, that produce feature maps with the same spatial dimensions as the original image. The rationale for using multiple-scale layers is to extract object features at various receptive field scales. Res-CR-Net offers the option of concatenating or adding the parallel branches inside the residual block before adding them to the shortcut connection. In our test, concatenation produced the best result. A Spatial Dropout layer follows each residual block. A slightly modified STEM block processes the initial input to the network. n CONV RES BLOCKS can be concatenated.
LSTM RES BLOCK. A new type of residual block features a residual path with two orthogonal bidirectional 2D convolutional Long Short Term Memory (LSTM) layers. For this purpose, the feature map 4D tensor emerging from the previous layer first undergoes a virtual dimension expansion to 5D tensor (i.e. from [4,260,400,3] [batch size, rows, columns, number of classes] to [4,260,400,3,1]). In this case the 2D LSTM layer treats 260 consecutive tensor slices of dimensions [400,3,1] as the input data at each iteration. Each slice is convolved with a single filter of kernel size [3,3] with ‘same’ padding, and returns a slice of the exact same dimension. In one-direction mode the LSTM layer returns a tensor of dimensions [4,260,400,3,1]. In bidirectional mode it returns a tensor of dimensions [4,260,400,3,2]. The intuition behind using a convolutional LSTM layer for this operation lies in the fact that adjacent image rows share most features, and image objects often contain some level of symmetry that can be properly memorized in the LSTM unit. Since the same intuition applies also to image columns, the expanded feature map of dimensions [4,260,400,3,1] from the earlier part of the network is transposed in the 2nd and 3rd dimension to a tensor of dimensions [4,400,260,3,1]. In this case the LSTM layer processes 400 consecutive tensor slices of dimensions 260,3,1 as the input data at each iteration, returning a tensor of dimensions [4,400,260,3,2] which is transposed again to [4,400,260,3,2]. The two LSTM output tensors are then added and the final dimension is collapsed by summing its elements, leading to a final tensor of dimensions [4,260,400,3] which is added to the shortcut path. m LSTM RES BLOCKS can be concatenated.
Hassan Abdallah et al 2020 Mach. Learn.: Sci. Technol. 1 045004
Source code for Res-CR-Net is deposited at: https://github.com/dgattiwsu/Res-CR-Net